
Executive Summary
- Financial institutions processing AML watchlist data face a unique ETL challenge: hundreds of data sources with incompatible schemas, daily update cycles, and zero tolerance for missed records.
- The four-layer ETL architecture described in this post (ingestion, normalisation, enrichment, deduplication, and load with lineage) was designed during our work on a global AML screening platform that processes 700+ watchlists.
- Incremental load strategies reduce processing time by 60-80% compared to full reloads, but require careful change detection logic when source lists do not provide reliable delta feeds.
- The ETL market is projected to grow from $8.85 billion in 2025 to $18.6 billion by 2030, with financial services accounting for 28% of total market revenue. If you are a CTO at a FinTech firm, your ETL architecture is a compliance infrastructure decision, not a data plumbing decision.
What is an ETL Pipeline in FinTech?
An ETL (Extract, Transform, Load) pipeline in FinTech is a data architecture that pulls financial records from source systems, applies compliance transformations, and loads structured output into a target database. It differs from general-purpose ETL because every transformation step must produce an auditable trail satisfying regulations like the EU’s AMLD6, the UAE’s CBUAE AML guidelines, and FinCEN’s BSA requirements. Unlike ELT patterns common in analytics workloads, FinTech ETL enforces data quality gates before data reaches the warehouse – because loading dirty compliance data and fixing it later is not an option when regulators ask for lineage.
Why ETL Architecture Matters More in FinTech Than Anywhere Else

If you are running data engineering for a FinTech company in 2026, the pressure comes from three directions at once.
The ETL market is expanding from $8.85 billion in 2025 to a projected $18.6 billion by 2030, and financial services accounts for 28% of ETL market revenue, with banks and FinTech companies leading adoption for regulatory compliance and risk management.
Regulatory velocity is accelerating. In fiscal year 2025, the U.S. SEC initiated 200 enforcement actions in just the first quarter. The EU’s AMLD6, the UAE’s updated CBUAE framework, and FATF’s expanded Travel Rule all demand compliance data that is traceable, timestamped, and reproducible on demand.
Source data is getting messier. AML watchlists arrive in CSV, XML, JSON, PDF extracts, and occasionally as HTML tables scraped from government websites. Some update daily. Others update irregularly with no changelog. False positives can account for up to 95% of all flagged transactions in poorly tuned screening systems, and the root cause is almost always upstream: bad data normalisation in the ETL layer.
Real-time expectations are table stakes. Banks and financial institutions are moving away from slow batch processing toward sub-second, streaming decision making. Batch-only ETL that ran overnight worked five years ago. It does not work when your screening engine needs to check a name against a sanctions list updated 90 minutes ago.
What Does a Production ETL Pipeline for AML Data Actually Look Like?

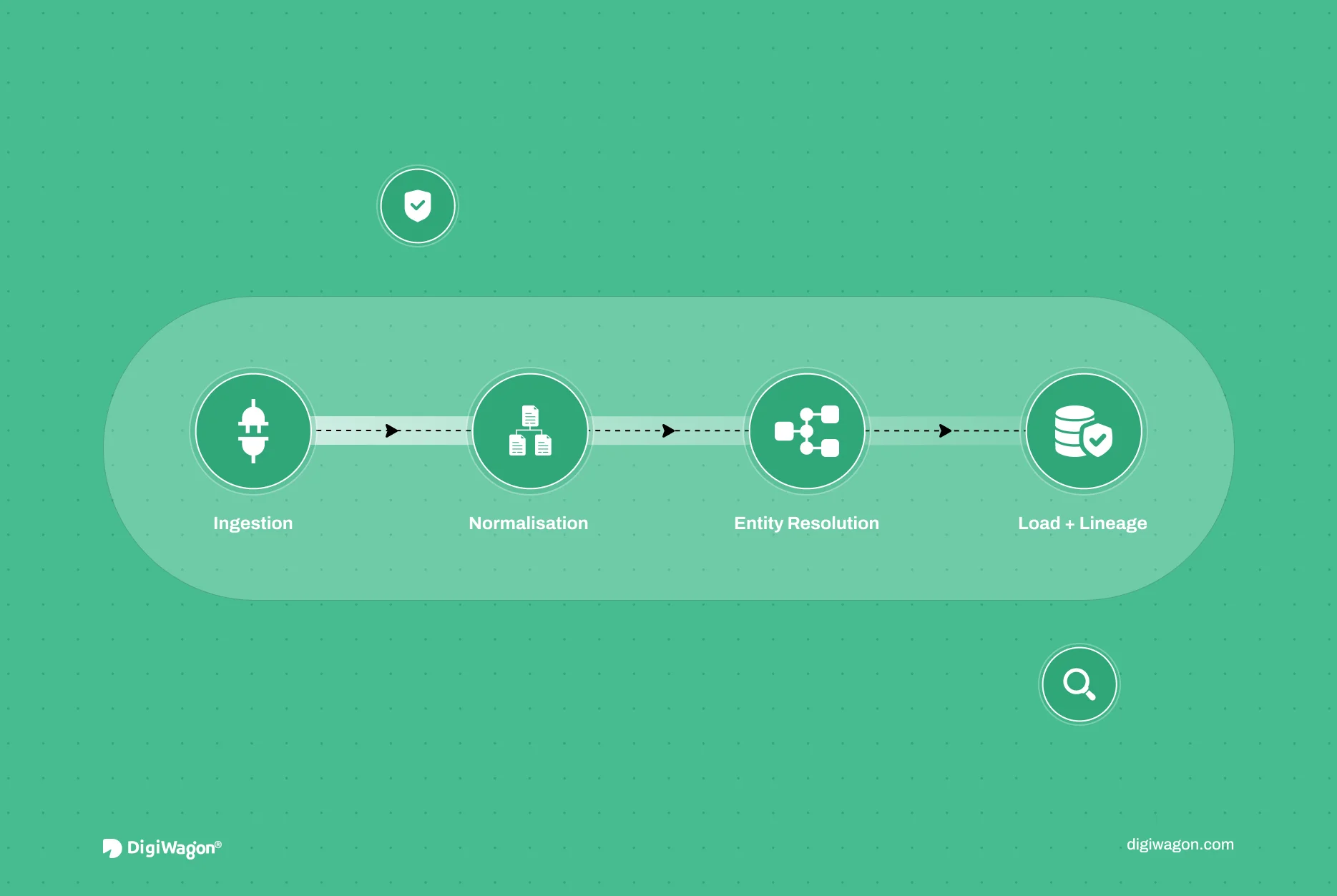
Most ETL content online shows a three-box diagram: Extract → Transform → Load. That works for a data warehouse migration. It does not work when you are processing AML watchlist data from 700+ global sources where a missed entity can trigger a regulatory fine.
Here is what a production-grade pipeline requires: four layers.
Layer 1: Ingestion and Source Connectors
The ingestion layer handles source diversity. For our AML compliance project, this meant building connectors for OFAC (CSV with fixed-width variations), UN Security Council lists (XML), EU consolidated sanctions (XML with nested entity structures), and dozens of national regulators publishing in formats from JSON to semi-structured PDF.
Each connector needs three things: a schema adapter, a freshness monitor (to detect whether a source has actually updated versus merely re-published), and a hash-based change detector.
The mistake most teams make: building one “universal” parser. It does not work. OFAC’s entity structure is flat. The EU’s is deeply nested with multiple aliases per entity. The UK’s HMT list uses a different date format than the Australian DFAT list. We settled on a connector-per-source-family pattern, grouping sources by structural similarity, not geography.
Layer 2: Normalisation and Schema Mapping
This is where AML ETL gets hard. A single sanctioned individual can appear across 15 different watchlists with 15 different name spellings, different date-of-birth formats, and different alias structures.
The normalisation layer handles name transliteration (Arabic, Cyrillic, Chinese scripts romanised consistently), date format reconciliation (DD/MM/YYYY vs. MM/DD/YYYY vs. “circa 1965”), entity type classification (person, organisation, vessel, aircraft), and field mapping to a canonical schema. We settled on a 47-field canonical entity schema after three rounds of iteration, the first version had 32 fields and missed vessel identification edge cases, the second had 61 and was over-normalised.
Layer 3: Enrichment and Entity Resolution
The enrichment layer cross-references entities across lists and appends supplementary data (additional aliases, known associates, linked corporate entities). It also applies jurisdiction-specific business rules, a UAE-regulated institution screens against CBUAE’s local list in addition to OFAC and UN lists, while a European bank adds EU and national lists for every member state where it operates.
After enrichment, deduplication merges multiple records referring to the same real-world entity. We combine deterministic matching (exact match on name + DOB + nationality) with probabilistic matching (Levenshtein distance for Latin-script names, Double Metaphone for transliterated names). The output is a “golden record” with provenance tags showing which source lists contributed which fields.
Layer 4: Load with Lineage
The final layer loads deduplicated entities into the screening database and writes a full lineage record: which source provided the data, when it was ingested, what transformations were applied, and which schema version was used.
This lineage trail is non-negotiable. When an auditor asks “why did your system flag this entity on March 15?” you need the complete chain: source list → ingestion timestamp → normalisation rules → enrichment data → deduplication decision → screening match.
| Layer | Function | Key Challenge |
|---|---|---|
| Ingestion | Source connectivity + change detection | Format diversity across 700+ sources |
| Normalisation | Schema mapping + transliteration | Multilingual name handling |
| Enrichment + Dedup | Cross-referencing + entity resolution | Fuzzy matching accuracy vs. false positives |
| Load + Lineage | Auditable write to screening DB | Full provenance chain for every entity |
Incremental vs. Full-Load: Which Strategy Works for AML Watchlists?
The textbook answer is “incremental loads are always better.” The AML answer is “it depends on whether the source gives you reliable deltas.”
When incremental works: OFAC provides a change log with additions, modifications, and deletions. The UN Security Council list includes publication dates per entry. Incremental loads on these sources reduced our daily processing from 4+ hours (full reload) to under 45 minutes.
When full-load is safer: Many national regulators publish a complete snapshot with no indication of what changed. For these, we use a “full-load-with-diff” pattern: load the complete snapshot into staging, run field-by-field comparison against the previous version, and promote only actual changes. It is slower than pure incremental but far more reliable for sources that do not version their data.
| Strategy | Best For | Processing Time Impact |
|---|---|---|
| Pure Incremental | Sources with changelogs (OFAC, UN) | 60-80% reduction vs. full load |
| Full-Load-with-Diff | Sources publishing full snapshots | 20-30% reduction (staging + comparison) |
| Full Reload | Initial loads, schema migrations | Baseline (100%) |
How Does Schema Evolution Work Across Regulatory Jurisdictions?
When the EU added cryptocurrency wallet address fields in its 2024 sanctions framework update, our canonical schema needed a new field type. When the UAE’s CBUAE expanded its list structure to include beneficial ownership chains, the entity model needed recursive relationships.
We handle schema evolution with a versioned schema registry. Every ingestion run tags records with the active schema version. Historical records are not retroactively migrated, they remain queryable under their original version. New fields are added as nullable columns with backward-compatible mappings.
This costs more storage than in-place migration. It saves you from the nightmare scenario: a regulator asks for historical screening results from 18 months ago, and your migration has overwritten the field structure that existed at the time.
Industry Context: Why FinTech ETL Is Different from Enterprise ETL
The Banking, Financial Services, and Insurance sector commands 24.12% of data integration market revenue. The spending is driven by regulatory necessity, not analytics ambition.
In healthcare, a data quality error might delay a report. In FinTech software development, a data quality error might mean your screening engine misses a sanctioned entity, a compliance failure that can result in fines measured in millions.
According to PwC, 62% of financial institutions already use AI and ML for AML activities, and this is expected to increase to 90% by the end of 2025. But AI screening models are only as good as the data feeding them. A model trained on poorly normalised watchlist data will produce more false positives, not fewer. The ETL pipeline is the foundation that makes AI-driven AML screening viable.
What We Learned Building ETL Pipelines for a Global AML Platform

DigiWagon built and maintains the data ingestion and transformation infrastructure for an AML compliance platform screening against 700+ watchlists. Three lessons stood out.
Variety was harder than volume. We expected the challenge to be processing millions of records quickly. The real challenge was source format diversity. One regulator publishes watchlist updates as a ZIP with three CSVs using different delimiters. Another publishes XML where aliases are stored as comma-separated values inside a single element. We spent six weeks building and discarding three “universal parser” approaches before settling on the connector-per-source-family pattern.
Transliteration accuracy drove the biggest quality gains. Our initial pipeline used Python’s Unidecode for all non-Latin scripts. It handled Arabic and Cyrillic reasonably but failed on Chinese and Korean names. Adding a language-detection step before transliteration, routing names to script-specific engines, dropped fuzzy match false positive rates by 34%.
Invest in lineage tooling from day one. For the first three months, lineage was a logging afterthought. When a client’s compliance team asked us to trace a screening match back to its source list and transformation path, it took two days of manual log analysis. After building a structured lineage layer (metadata tagging + a dedicated lineage table), the same query took under 30 seconds.
Read more about the platform on the AML compliance case study page.
Strengthen Your FinTech ETL Pipeline
Review your AML data flow for reliability, auditability, and scalability
Actionable Takeaways
- Audit your source connectors before optimising transformations. Map every source by format, update frequency, and delta reliability. Build connector families, not universal parsers.
- Implement script-aware transliteration for multilingual name data. Route names through language detection before transliteration. A single library will not handle Arabic, Cyrillic, Chinese, and Korean with equal accuracy.
- Use full-load-with-diff for sources without reliable change logs. Incremental logic on sources publishing unversioned full snapshots is a reliability trap.
- Define your canonical schema through iteration, not upfront design. Start with minimum viable fields, run against 50+ real sources, and expect three revision rounds.
- Build structured lineage from day one. Log-file-based lineage is technically auditable but practically useless under time pressure.
- Separate jurisdiction-specific rules from core transformation logic. UAE screening rules differ from EU rules differ from US rules. Hardcoding jurisdiction logic into transformation functions creates maintenance burden that scales with every new market.
How DigiWagon Can Help
DigiWagon’s enterprise ETL pipeline development services cover the full lifecycle from source analysis through production deployment for regulated data environments. We designed and maintain the data ingestion infrastructure powering a global AML screening platform that processes 700+ watchlists across OFAC, EU, UN, and dozens of national regulators daily. Schedule a free data pipeline architecture review to assess your ETL infrastructure against AML compliance requirements for your target jurisdictions.