Governed Enterprise AI Agents: Key Takeaways
- The enterprise blocker for AI agents is governability, not model capability. An agent you cannot audit or constrain cannot be deployed in a regulated process.
- “Autonomous agent” is the wrong mental model. Full autonomy is the last stage of a deployment path, not the starting point.
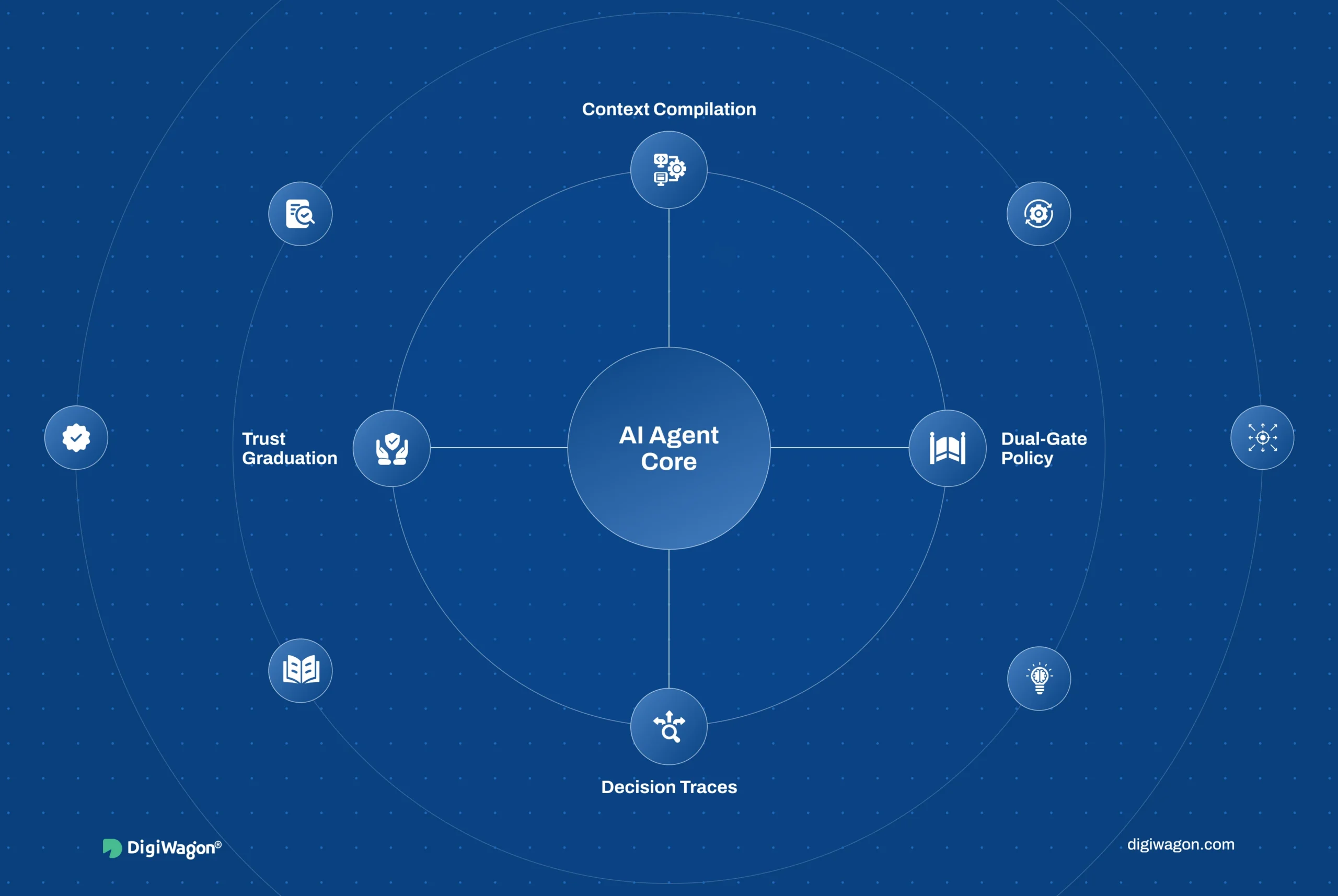
- Governance has four control surfaces: context compilation, dual-gate policy enforcement, decision traces, and trust graduation.
- A single policy gate is not enough. Policy has to hold before the agent reasons and again before it acts.
- Decision traces designed in from day one make an agent audit-ready by default, not retroactively.
- Autonomy is earned through measured evaluation, moving from shadow mode to bounded autonomy one stage at a time.
What a Decision Harness Is

A decision harness is an architecture pattern for governed enterprise AI agents that wraps four control surfaces around an agent: context compilation, dual-gate policy, decision traces, and trust graduation. It governs what the agent may know, what it may do, what it leaves behind as a record, and how much autonomy it has earned. The output is an agent whose every action is constrained, reconstructable, and bounded by deployment stage.
Why Do Enterprise AI Agents Stall on Governability, Not Capability?

Most enterprise agent pilots clear the capability bar in a week. The model can draft the response, triage the alert, or route the case. Then the project stops, and it stops in the same place every time: nobody can explain to the risk committee how the agent will be controlled, audited, and trusted.
The framing of “autonomous agent” is part of the problem. It puts autonomy at the front of the conversation when autonomy is the thing an enterprise grants last, after everything else has been proven. A CTO does not lose sleep over whether the agent is clever enough. The sleepless question is what happens the first time it acts on bad context, or takes an action no one can reconstruct six months later when a regulator asks.
This is the gap the NIST AI Risk Management Framework names directly. NIST AI RMF 1.0 (NIST, 2023) organizes trustworthy AI around four functions: Govern, Map, Measure, and Manage. Notice that “Govern” comes first. The framework treats governance as the foundation the rest sits on, not a control bolted on after the model works.
A capable agent without a governance architecture is a liability with good benchmarks. The rest of this post is the architecture that closes the gap.
Context Compilation: What Should a Governed Enterprise AI Agent Be Allowed to Know Before It Acts?
The first governance gate is upstream of reasoning. Before an agent decides anything, something has to decide what it is allowed to see. That is context compilation: the deliberate assembly and scoping of the data, tools, and memory an agent receives for a given task.
Treating context as “everything we can retrieve” is the most common early mistake. An agent handed unrestricted retrieval will pull data it has no business acting on, and every downstream control inherits that contamination.
Context compilation governs three things:
- Data scope. Which records, documents, and fields enter the working context for this task, and which are explicitly excluded.
- Tool scope. Which tools and external calls the agent may invoke at all, before it ever forms an intent to use one.
- Memory scope. What persists between turns and sessions, and what is deliberately forgotten so a stale fact cannot resurface as a fresh decision.
When the firm’s data-handling policy requires that an agent never sees data outside a customer’s consent boundary, the architectural response is a compiled context that filters at assembly time, not a prompt instruction asking the model to behave. Instruction is a request. A compiled, scoped context is a constraint the model cannot talk its way around.
| Approach | What it governs | Failure mode |
|---|---|---|
| Open retrieval | Nothing; agent sees what it can fetch | Acts on out-of-scope or stale data |
| Prompt-level restriction | Model is asked to self-limit | Prompt injection or drift overrides it |
| Compiled context | Data, tool, and memory scope set before reasoning | Constrained by construction, not by request |
The principle generalizes beyond data. ISO/IEC 42001:2023, the AI management system standard, frames governance as something built into the system lifecycle rather than inspected at the end. Context compilation is that principle applied to the agent’s inputs.
[Teams designing this layer can see how enterprise AI agent development covers context scoping through production deployment.]
The Dual-Gate Pattern: Why Check Policy Before Reasoning AND Before Execution?
Single-gate designs are where most agent governance quietly fails. A team adds one policy check, usually at the end, right before the agent executes an action, and assumes the gate is covered. It is not.
The dual-gate pattern enforces policy at two distinct points:
- Pre-reasoning gate. Before the agent reasons, policy validates the inputs, the scope, and the intent the task implies. This catches the problem early: an agent that should never have been allowed to consider an action does not get to consider it.
- Pre-execution gate. After the agent reasons and proposes an action, policy validates the specific action against the rules before anything happens in the real world. This catches the problem an agent can introduce during reasoning that the pre-reasoning gate could not predict.
Why both? Because the two gates catch different failures. A pre-execution-only design cannot stop an agent from reasoning over data it should never have touched. A pre-reasoning-only design cannot stop an agent that was given clean inputs but proposes an unsafe action anyway, which is exactly what prompt injection and tool-call manipulation produce.
The OWASP Top 10 for LLM Applications (OWASP, 2025) catalogs these as live threat classes: prompt injection, insecure output handling, and excessive agency. A single gate leaves one side of the attack surface open. The dual-gate model assumes the agent itself can be turned into the attack vector, which is the correct assumption for any agent exposed to untrusted input.
When the firm’s risk policy requires dual approval on a material action, the pre-execution gate is where that human-in-the-loop check lives, enforced through an access-controlled path rather than a convention people are trusted to follow.
This failure mode is the subject of a dedicated sibling analysis. For the security-specific treatment of agents turned into attack vectors, see preventing autonomous threats in agent deployments.
Decision Traces: How Do You Make an AI Agent Audit-Ready by Default?
An agent that cannot explain what it did, in a form a third party can reconstruct, is an agent a regulated enterprise cannot run. The architectural answer is the decision trace: a structured, immutable record of every input, every policy gate result, every reasoning step, and every action, captured as the agent runs rather than reconstructed afterward.
“Reconstructed afterward” is the trap. Logging that was added to debug the system is not the same as lineage designed to answer an audit. The first is incidental and lossy. The second is a deliberate system of record. Audit-readiness is a property you design in at the schema level, not a report you generate under deadline.
The EU AI Act makes this concrete for high-risk systems. It requires automatic logging and record-keeping over the system’s lifecycle and human oversight provisions, with high-risk obligations phasing in on a staged schedule through 2027 (European Union, 2024). For any agent operating in a regulated process, the decision trace is not optional documentation. It is the artifact the regulation assumes exists.
A decision trace designed for audit-readiness captures, per action:
- The compiled context the agent received, scoped exactly as it was at decision time.
- The result of each policy gate, pre-reasoning and pre-execution.
- The reasoning the agent produced and the action it proposed.
- The final action, its outcome, and any human approval recorded against it.
When compliance requires reconstructable decisions, the architectural pattern is immutable, append-only lineage versioned from the first action, so the trace shows what was true at the moment of every past decision, not what the system looks like today. This is the same auditability discipline explored for broader compliance systems in designing auditable AI for European compliance.
Trust Graduation: From Shadow Mode to Bounded Autonomy
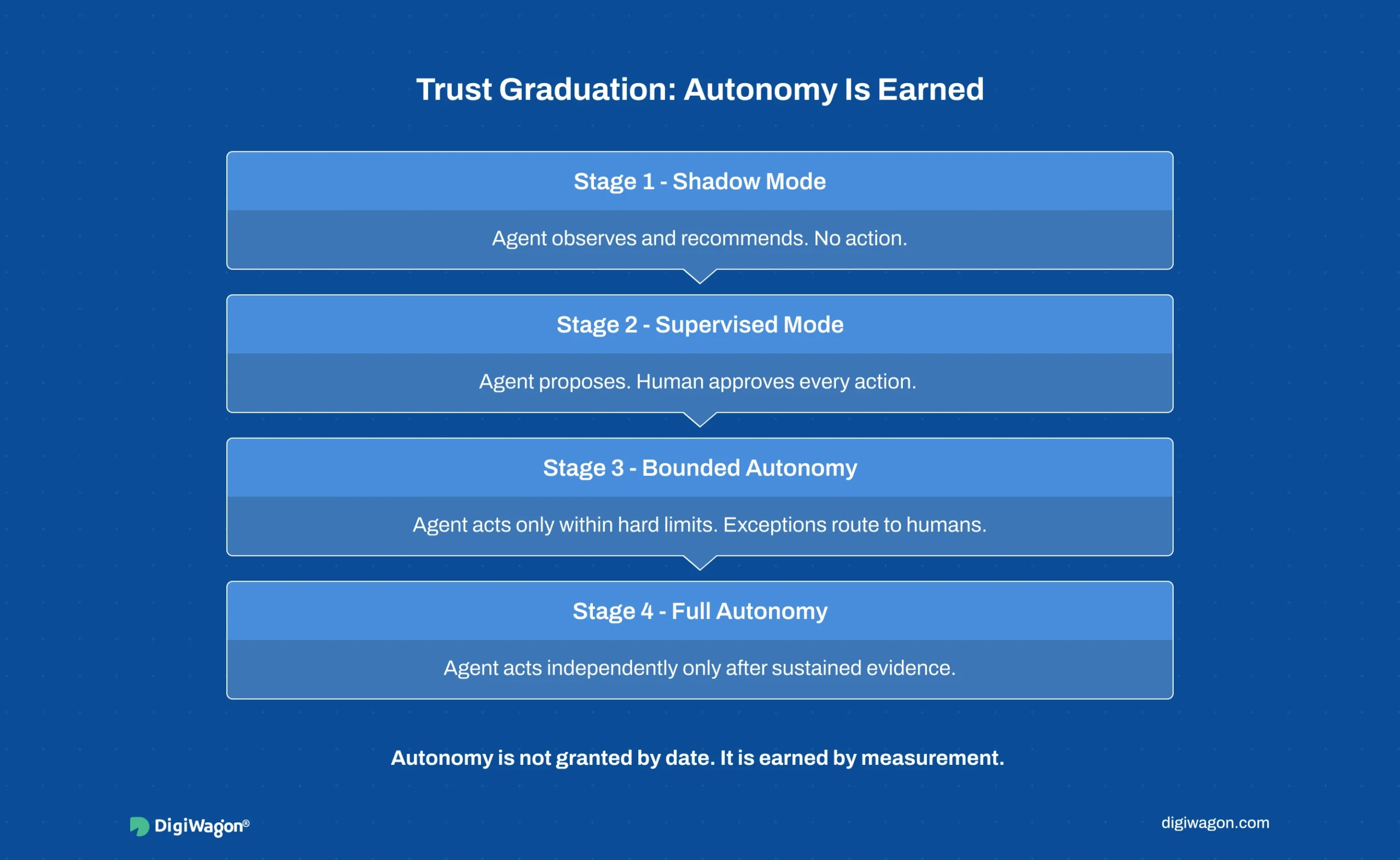
Autonomy is not a switch. It is a path an agent earns one stage at a time, with measured evaluation gating each promotion. We call this trust graduation, and it is the discipline that turns “we deployed an autonomous agent” from a risk into a sequence of controlled, reversible steps.
The four stages:
| Stage | What the agent does | What the human does | Promotion criterion |
|---|---|---|---|
| Shadow | Proposes actions; nothing executes | Acts independently; agent observed | Measured agreement with human decisions over a defined volume |
| Supervised | Proposes actions; human approves each | Approves or overrides every action | Low override rate on a defined action class |
| Bounded | Acts autonomously within hard limits | Reviews exceptions and out-of-bound cases | Stable performance inside the bound |
| Full | Acts autonomously across the task | Audits via decision traces | Reserved; many regulated processes stop at bounded |
Each promotion is a decision backed by data from the decision traces, not a calendar date. The NIST AI RMF’s Measure function maps directly onto this: you promote an agent when measurement supports it, and the trace is what you measure.
Two honest points. First, many regulated processes should stop at bounded autonomy and never reach full. That is not a failure of the architecture; it is the architecture working as intended. Second, trust graduation only works if the earlier surfaces are in place. You cannot measure agreement without decision traces, and you cannot promote safely without the dual gates holding at every stage. The trust-graduation discipline is treated in depth in its own supporting analysis, queued in this cluster.
What We’ve Actually Built, and What This Architecture Extends Toward
A note on honesty, because it matters for how you read everything above. DigiWagon has not shipped a single packaged “governed-agent platform,” and the decision harness is not a product on a price sheet. It is the architectural position we argue for, grounded in components we have built and extended toward the full pattern.
What is shipped: on AML screening and decisioning work, we built the evaluation and accuracy layer that scores model output before it is trusted, the guardrail approach that constrains what the system is permitted to do, and the audit and lineage components that make decisions reconstructable. On that work we chose PostgreSQL as the canonical lineage store over a document store, because audit-reconstruction and version-diff queries are relational and benefit from foreign-key constraints and strong typing; the schema flexibility a document store offers was not worth the lineage-query complexity it introduced. The detail behind that work sits in our AI-powered AML screening platform and global AML software case studies.
What extends: the full four-surface decision harness, applied to general enterprise agents, is the architecture we are arguing toward from that shipped foundation. We are honest about the line between the two, because a build partner that blurs it is one you will not trust on the next claim.
Building Governed Agents with DigiWagon
DigiWagon designs agent governance architecture for regulated enterprises, grounding the work in shipped evaluation, guardrail, and lineage components rather than a packaged platform.
- Context-compilation design: data, tool, and memory scoping
- Dual-gate policy enforcement across the agent lifecycle
- Decision-trace and lineage schemas built for audit-readiness
- Trust-graduation evaluation harnesses from shadow to bounded autonomy
Where Governed Enterprise AI Agents Go Next in Regulated Industries
The agent conversation in regulated industries is moving off capability and onto control, and that shift favors teams that treat governance as architecture rather than paperwork. The four surfaces hold together as a system: context compilation governs what the agent knows, the dual gates govern what it does, decision traces make it reconstructable, and trust graduation bounds how far it goes. Get those right and the model choice becomes a detail, swappable underneath a harness that does not change. The next move is industry-specific: how the harness lands in FinTech onboarding, in RegTech software architecture, and in FinTech platform engineering, where the regulatory clock is already running. Teams that build the harness now will have agents in production while the rest are still explaining their pilots to the risk committee.
Planning a Governed Agent Deployment?
Our engineering team designs the control surfaces that make enterprise agents auditable and deployable.