AML Screening Engines: What Actually Matters
- An AML screening engine is a retrieval-and-scoring system, not a database lookup; the retrieval architecture determines accuracy more than the list does.
- Pure vector similarity fails on transliterated names; hybrid retrieval combining vector and phonetic matching is the architecture that holds across scripts.
- Real-time sanctions screening runs against a latency budget; a caching layer over the resolution path is what makes sub-second decisioning achievable.
- Regulated-data clients need per-tenant data isolation at the index level, which is an architectural choice made before the first tenant onboards, not after.
- The screening engine reads from the watchlist data pipeline; a clean pipeline upstream removes most of the noise the engine would otherwise compensate for.
An AML screening engine is the retrieval-and-scoring system that matches customers, counterparties, and transactions against sanctions and watchlist data, then returns a structured decision with reason codes and a version-bound evidence pointer. The engine’s accuracy is set by its retrieval architecture, not by the size of the list it screens against.
Why the Retrieval Architecture Is the Real Engine
A screening engine is often described as “matching names against a list,” which undersells the hard part. The list is reference data. The engine is the retrieval and scoring system that decides, in milliseconds, whether an incoming name is the same entity as a sanctioned one despite spelling variance, transliteration, name-order differences, and partial information.
The Wolfsberg Group’s sanctions screening guidance is explicit that screening effectiveness is a function of data quality and matching logic together, not list coverage alone. A larger list screened by a weak retrieval architecture produces more false positives, not better coverage. The architectural question is how the engine retrieves candidate matches and scores them, because that pipeline is where accuracy and latency are won or lost.
This engine reads from the upstream AML watchlist data pipeline architecture; the cleaner the pipeline’s canonical schema, the less variance the engine compensates for at query time.
What Are the Core Components of an AML Screening Engine?

A production screening engine has four components, each a distinct architectural concern.
The retrieval layer pulls candidate matches from the indexed watchlist data. This is where vector similarity, phonetic matching, and exact-match indexing live.
The scoring layer ranks candidates by match confidence and applies thresholds. A candidate above the auto-alert threshold raises an alert; one in the review band routes to a human; one below is suppressed.
The decision layer packages the outcome as a structured record: the match (or no-match), the reason codes, the watchlist version bound to the decision, and an evidence pointer. This is the contract the downstream case-management workflow reads.
The caching layer sits across retrieval and scoring to meet the latency budget, holding hot index segments and recent resolution results in memory.

The deeper detection-model work (the embedding models and ranking functions inside the retrieval and scoring layers) belongs to the AI and ML engineering practice; the four-component architecture is the engine’s skeleton regardless of which models populate it.
How Does Hybrid Retrieval Beat Pure Vector Search?
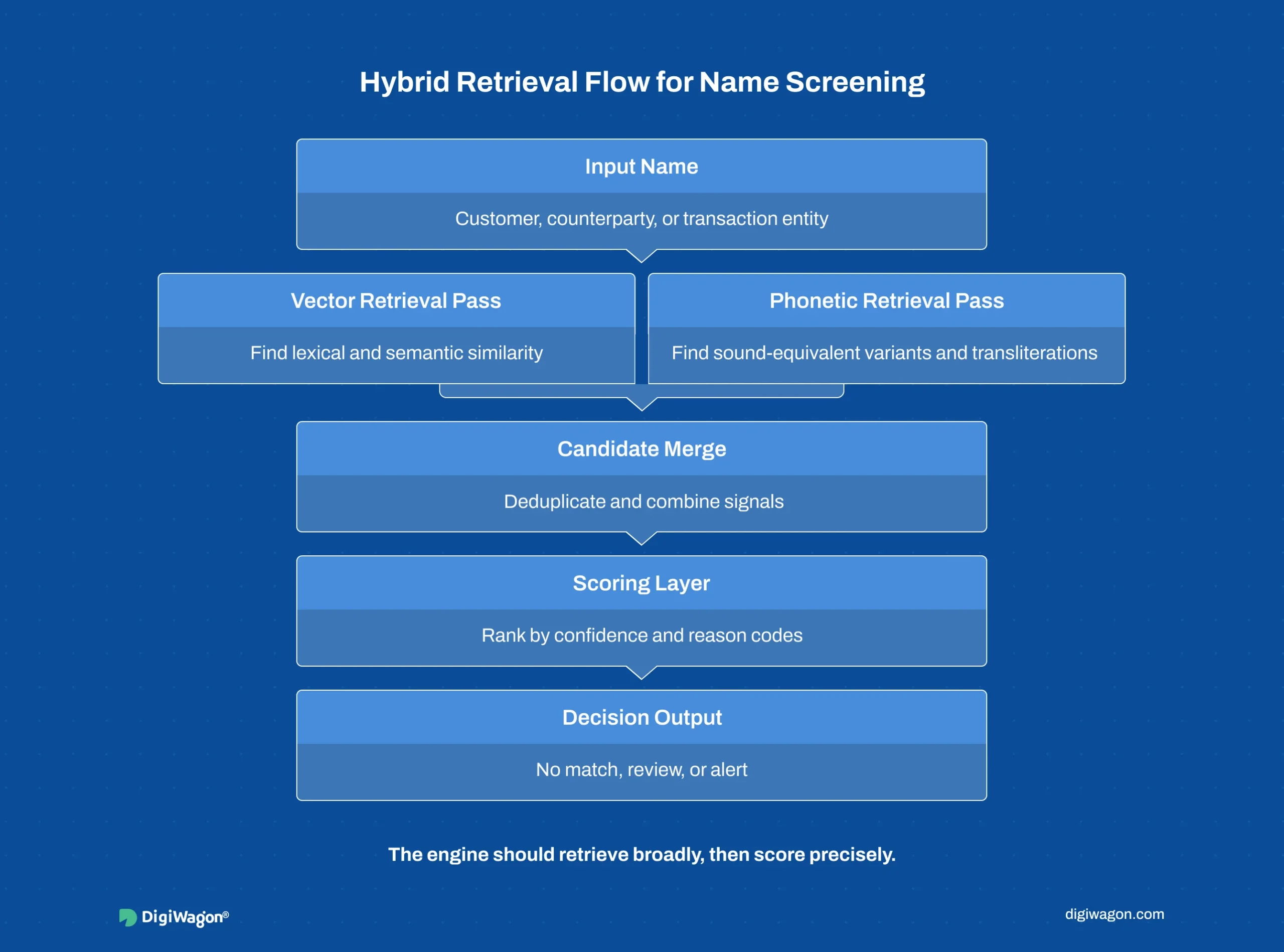
Pure vector similarity search is the seductive default for fuzzy name matching. It works well for Latin-script spelling variants. It fails on transliteration.
A name rendered from Arabic or Cyrillic into Latin script has many valid spellings, and the variance is phonetic, not lexical. Vector embeddings trained on text similarity treat two valid transliterations of the same name as distant when they share sound but not spelling. The ICAO Doc 9303 transliteration standard exists precisely because cross-script name rendering is non-deterministic; an engine that assumes one canonical spelling per name will miss matches the standard itself anticipates.
The architecture that holds is hybrid retrieval: vector similarity for semantic and lexical proximity, run alongside phonetic matching (Soundex, Double Metaphone, language-aware tokenisation) for cross-script sound equivalence. The two retrieval passes feed a combined candidate set into the scoring layer.
| Retrieval Approach | Strength | Failure Mode |
|---|---|---|
| Pure vector similarity | Latin-script spelling variants, semantic proximity | Transliterated names across scripts; sound-equivalent spellings score as distant |
| Pure phonetic matching | Cross-script sound equivalence | Floods scoring layer with low-relevance candidates; weak on non-phonetic variance |
| Hybrid (vector + phonetic) | Coverage across scripts and variance types | Higher engineering complexity; two indexes to maintain |
The hybrid cost is real: two indexes, two retrieval passes, a merge step. When the client screens names across multiple scripts, the coverage gain is worth the complexity. When the client screens Latin-script names only, hybrid is over-engineering.
How Do You Hit a Sub-Second Screening Latency Budget?
When screening runs at payment authorisation rather than in a batch sweep, latency is an SLA, not a preference. A real-time sanctions check that adds noticeable delay to a payment is a broken architecture regardless of its accuracy.
The latency budget is consumed by retrieval (index lookups across two passes in a hybrid engine), scoring (ranking and thresholding), and the decision-record write. Batch-style retrieval that re-queries the full index per request will not hit a sub-second budget at production volume.
The architecture that meets it is a caching layer holding hot index segments and recent resolution results in memory, fronting the retrieval path. Most screening traffic queries a small, stable subset of the watchlist; caching that subset collapses the common-case latency while the cold path falls through to the full index. The cache invalidates on watchlist version change, so a republished list does not serve stale matches. The NIST Cybersecurity Framework 2.0 Detect function, formalised February 2024, frames continuous, real-time detection as an architectural expectation rather than a periodic activity, which is the design posture a sub-second screening path is built for.
Teams architecting real-time screening can see how custom RegTech integration architecture places the engine inside the broader four-layer compliance pattern.
How Do You Architect Multi-Tenancy for Regulated Screening Data?
A screening platform serving multiple regulated clients faces a data-isolation decision that is hard to reverse. Shared-index multi-tenancy (all tenants’ data in one index, partitioned by tenant key) is cheaper to run and simpler to scale. It also makes data-residency guarantees difficult, because a single index is a single storage location.
When clients are regulated financial institutions, several will have data-residency requirements that forbid their data sharing storage with other tenants or crossing jurisdictional boundaries. The architecture that satisfies this is per-tenant index isolation: each tenant’s watchlist and screening data lives in a dedicated index, deployable to a specific region. The isolation is set at the index level, before the first tenant onboards, because retrofitting tenant isolation onto a shared index is a migration, not a configuration change.
The trade-off is operational cost and scaling complexity: more indexes to provision, monitor, and update. For regulated-data clients, the residency guarantee is non-negotiable, so the cost is the price of serving the market at all.
DigiWagon’s Role in AML Screening Engine Engineering
DigiWagon engineers AML screening engines as production systems: hybrid retrieval architecture, scoring and thresholding design, real-time latency engineering, and per-tenant data isolation. The work draws on the RegTech software development practice.
- Hybrid retrieval design (vector plus phonetic) for cross-script matching
- Caching architecture for sub-second real-time screening
- Per-tenant index isolation for data-residency compliance
- Structured decision contracts with version-bound evidence
Engineering Screening Engines That Hold Across Scripts
A screening engine is judged by what it catches and how fast, across every script its clients operate in. The architecture that delivers it is hybrid retrieval for cross-script accuracy, a caching layer for real-time latency, and per-tenant index isolation for data residency. Each is a decision made at design time, not patched in after the first regulator query or the first client with a residency clause. Engines built to the pattern hold their accuracy and their latency budget as the list, the scripts, and the tenant count grow.

Planning an AML Screening Engine?
Our engineering team works through retrieval architecture, latency budgets, and tenant isolation with your compliance and engineering teams in one room.